
Generated by ChatGPT
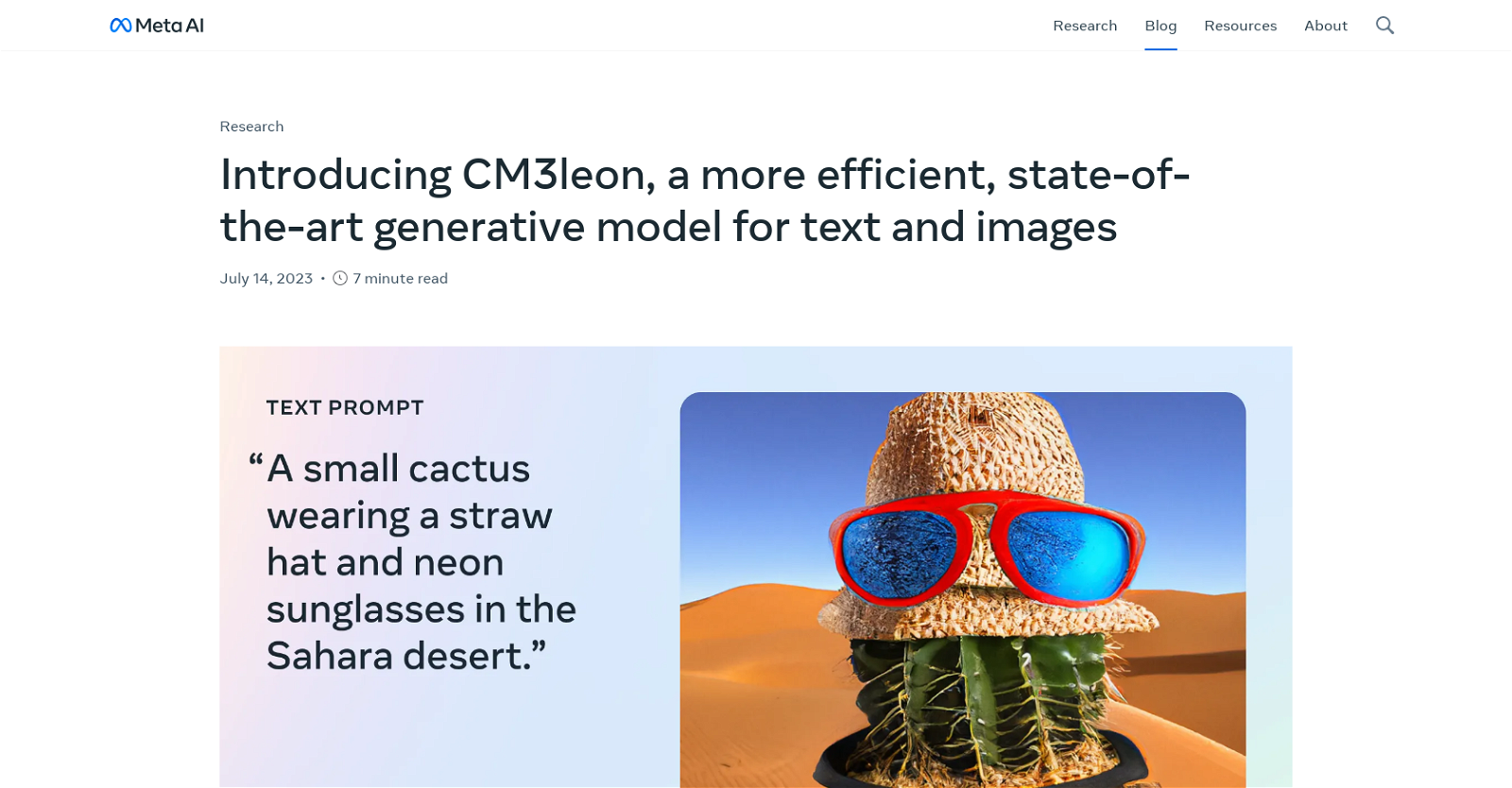
CM3leon is a state-of-the-art generative model that enables both text-to-image and image-to-text generation. It is a multimodal model that combines the functionality of autoregressive models with low training costs and inference efficiency. The model is trained using a recipe adapted from text-only language models, including retrieval-augmented pre-training and multitask supervised fine-tuning stages.CM3leon achieves state-of-the-art performance in text-to-image generation, even with five times less compute than previous transformer-based methods. It is capable of generating sequences of text and images conditioned on arbitrary sequences of other image and text content, expanding the functionality of previous models that were limited to either text-to-image or image-to-text generation.The model has been multitask instruction-tuned for both image and text generation, resulting in significant improvements in tasks such as image caption generation, visual question answering, text-based editing, and conditional image generation. CM3leon outperforms Google’s text-to-image model and achieves an impressive Fréchet Inception Distance (FID) score of 4.88 on the widely used image generation benchmark, establishing a new state of the art.CM3leon’s capabilities shine in complex object generation and text-guided image editing tasks. It excels in generating coherent imagery that follows input prompts, even when dealing with constraints and compositional structures. Moreover, the model performs well in tasks such as text-guided image editing, text-to-image generation with compositional prompts, and answering questions about images.Despite being trained on a relatively small dataset, CM3leon’s zero-shot performance compares favorably against larger models trained on more extensive datasets. It demonstrates the potential of retrieval augmentation and the impact of scaling strategies on autoregressive model performance. CM3leon’s versatility and excellent performance make it a valuable tool for various vision-language tasks.
Imaging & editing with versatile creative capabilities.

Stunning image generation for creatives and individuals.
Elevate your content with stunning visuals created directly from your writing.
Stunning image generation for art and design purposes
Generated custom images
Toolkit of magic for image generation and custom emojis.
Matchmaking by personal preferences & compatibility.
Transforming text prompts into stunning art instantly.
Generates high-res images from prompts.
Customized stock image and illustration generation. (0)
Art prompt creator.
Unable to detect tagline. Created: 'QBitMap, your AI assistant for image curation.'
Digital art generation without a watermark.
Dashboard for customizable art image generation.
Generated unique artworks using advanced algorithms.
Artvisio generates enhanced visual art.
Transforms textual descriptions into visual content.
Generate captivating unique artworks.
Image and art chatbot for Telegram.
Generating art from text or rough drawings.
Create unique Funko Pops with our AI Generator!
Generated diverse images with one prompt.
Interactive creation of images for web apps.
Created smart websites, chatbots, and assistants.
Generated graphic design for marketers/bloggers.
Produce impressive photos with AI for personal branding and social media.
Image customization solution for diverse outputs.
Web-based platform for creating and sharing art.
Create artworks with Stable Diffusion using a local GUI.
Generated photo art from user prompts and styles.
Image generation
Rapid, diverse image generation from prompts.
Generate unique digital art
Generates personalized art photos.
Web App Image Generation
Text-based image and artwork generation app.
Stunning art designs created with image generator.
Low-budget copyright-free image generation.
Automate any workflow with StableCascade.
Assisting with digital art creation and design.
Suite for enhanced content creation and editing.
Art-generated experimentation with diffusion models.
Customize pictures with filtered suggestions.
Analyzed and labeled data for diverse industries.
Revolutionizing your digital art experience.
Generates images from text on mobile.
Captivating, distinct visual content creation
Custom images for WordPress websites
Generated artwork for artists and designers
Image creation, editing, and restoration made easy.
Personalized image generation
Generated visuals from text descriptions.
Creation of visuals through intuitive prompts.
Craft art and writing with versatile utilities.
Prompts transformed into appealing images.
Generates Mac compatible visuals.
Quickly generating and finding visual content.
Generates realistic image avatars.
Easy creation of style-consistent art assets.
Generate creative images with your words.
Customizable photorealistic image generation.
Interactive image generation from written sentences.
Generative art with style and community sharing
Mobile app that generates unique art from text inputs.
Create unique artworks through text input.
Explore OpenAI's DALL·E capabilities like image generation and editing.
Generate hyper-realistic AI images for free
Digital art creation and animation for smartphones.
Generates custom images from user inputs.
Create stunning art with our AI image generator.
Generates descriptive images and text.
Assisted image generation application for Apple devices.
Generated art creation prompts.
Creating the most capable text-to-image model with improved performance.
Simplified design process for creative professionals.
Artwork creation platform for advanced artists.
Art generated on Mac.
Product photo editing and background removal.
Discover, inspire, and create images.
Image generation and customization.
Image generation for developers.
Transform Reality into Artistry!
Customized merchandise design with user input.
Creator content generated interactively.
App for creating unique ai-generated art images.
Leverage DALL-E 3 and GPT-4 Vision to generate a chain of images
Image generation for individuals and businesses.
Creates photorealistic and surreal art from text.
Supporting ideation, visualization, collaboration.
Generated personalized images via intuitive dashboard.
Generated stunning digital art from images.
Showcased generative art.
Art generation for inspiration & creativity.
Unleash Your Creativity with Our Free AI Image Generator
Generated artistic designs and images.
Instantly generate realistic and fantasy art for free.
Create & sell unique artworks: platform.
Efficient visual content creation.
Generated art.
Transformation of text into visual content for branding.
Neural network generates unlimited unique images.
Assisted digital art creation.
Cloud-based image editing and generation application.
Art & entertainment image generation.
Generate art from keywords for commercial/personal use.
Craft exceptional images with our advanced AI-driven tool.
An AI layer enhancing your desktop applications.
Design image generator and editor.
Generate creative images from text with various styles.
Image generation from text prompts.
Create images like never before!
A software that fills in missing parts of an image.
Creation of photorealistic digital art on mobile.
Captivating visuals from text
App that generates art from user's prompts.
Creating unique images through user prompts.
Generating artistic images with AI.
Quickly create digital art with image generator.
Image generation for blogs and illustrations.
Generated stunning visual art pieces via mobile app.
Enhanced photo editing with advanced capabilities.
Generating art from dream images.
Transform your ideas into transparent PNGs in seconds.
Scalable image and text gen for devs.
Personalized assistants for health and relationships.
Create stunning and unique images with ease using our AI.
Building controllable AI models for visual expression.
Automated image generation for art and design projects.
Customizable, efficient image creation for artists.
Create imaginative images using prompts.
Unleash creativity from text, transform your ideas into stunning images.
Prompts inspire art creation.
Convert text to images for design creation.
Efficient image creation & editing for creatives.
Generate images from text on Apple Silicon.
Platform generating printed art from memories.
Generated images from Notion prompts.
A platform for creating infinite designs.
Automated content generation.
Generate branded images in specific styles.
Generated unique art models.
Generated images for online or personal projects.
Generated images at speed, with variety.
Image generation using text prompts.
Free online tool for building Stable Diffusion workflow
Image feedback collection for research.
Created images collaboratively with SDXL model.
Customized online shopping for unique designs.
Unique art sales through online platform.
Shared visual collaboration with instant annotation.
Experimenting with creative mediums of thought.
Selfies turned into personalized Halloween art.
Generated creative content creation.
Generates custom stock photos from user descriptions.
Custom image generation interface
An app for generating unique mobile art.
Image synthesis from text prompts, instantly.
Convert text to attractive images easily.
Effortlessly edit images without expertise or downloads.
Create diverse art with this platform.
An app for generating mesmerizing artworks and avatars.
Graphic design and image editing for platforms.
Stock imagery library with generated pictures.
Limitless art generated.
An app for creating art from user concepts.
Art collection generated by machines online.
Enhance Your Photos With The Power of AI
Create photorealistic AI shots.
First AI image generator for creatives.
Captivating anime art generated by advanced algorithms.
Rapidly creates diverse images for multiple needs.
Created digital art with diverse styles using models.
Generating gorgeous pictures based on your requests.
Generate artwork & illustrations for creativity.
Generated surreal images for inspiration.
Affordable, high-quality image/art generation
Image generation
Turning your creative ideas into breathtaking images.
Artistic image enhancement for businesses and artists.
Text-to-image for devs and users.
Image composer
Customizable image generation and assisted drawing.
Generate vector illustrations from text prompts.
Generating art easily without technical expertise.
Artwork-based royalty-free animations.
Artistic image and NFT platform promoting creativity.
Automated art creation.
An app for creating and editing images.
Curated personalized portraits from images.
Image generation from text or keywords.
Generate AI photos from your uploaded pictures.
Automated graphic design creation.
Created high-quality art and design images.
Creating stunning AI art with ease.
Generated images for graphics and illustrations.
Generates art with presets and editing features.
Image creation for designers using trained algorithms.
Advanced algorithm for expressive image creation.
Prompt-based paintings in various styles.
Customizable images generated from text prompts.
Generate and edit images for designers.
Create and edit images with AI, effortlessly.
Generate images using prompts, no design skills needed.
An intuitive platform for creating unique art.
Unlimited creative assets generation and style training.
Showcased digital artwork on web platform.
Generate photos with AI models for FREE!
Advanced image generation platform for creators.
Prompt Art enables marketing graphic design.
Create collaborative art for artists and designers.
Creates 2+1D VR environments.
Extracted text, generated images, translated language.
Open-source text-to-image collaboration platform.
Art discovery engine for generated inspiration.
Enhanced messaging with contextually appropriate images.
Image generation
Browse and discover on mobile.
Image generation from text prompts.
Edit photos with voice commands.
Easy art generation with text prompts.
Generated art and videos with hot diffusion modes.
Automated background removal for portrait images.
Eases image API testing, generates custom images.
Image generation from text input.
Image generation for unique and themed images.
Get creative with Artiverse's online AI image generation tools.
Generates images for architectural and interior design.
Generated controllable art creation.
Image editor plugin with In/Outpainting & modifiers.
Edited images with erased objects, upscale, and filters.
Visual storytelling and identity exploration.
Transforming Your Vision into Visual Masterpieces!
Assisted image creation through quick sketching.
Automation and prototyping for designers.
Art creation in Discord with automated intelligence.
Generated fictional Pokemon imagery.
A user-friendly photo editor with written instructions.
Personalized artwork creation and exploration.
Create custom characters via prompts and poses.
Converts text to visually appealing images.
Transform creative visions into stunning visuals with Idyllic, the generative AI platform.
Image editor with intuitive masking capabilities.
Visualize your ideas with AI-generated images.
Generated images from text input.
Generating images through text.
Creation of art and image generation.
Creating customizable digital artwork.
An AI image generator for designers, marketers, and agencies.
Generated images from text prompts.
Image generation for unique stock images and artwork.
Art discovery & community platform.
Translated image prompts.
Custom anime illustration creator.
Generate stunning designs in seconds and create your own personalised products
Social media art gallery generator.
Transform your ideas into stunning visuals.
Photorealistic Images With Custom Settings
AI to generate amazing photos.
Limitless creative possibilities with generated images.
Platform providing stock photos for diverse projects.
Collaborative drawing with image prompts.
Creative asset refining for artists/designers.
Generate art with Stable Diffusion and Kandinsky models.
Platform for graphic and text design templates.
Dream-like image sharing and creative exploration.
Connecting AI Art Like Tetris
Artistic image creation from text inputs.
Illustration creation for content projects.
Art and image creation using text descriptions.
Design and visualization of creative projects.
Create mesmerizing generative artworks.
Unfettered access to the realm of creativity with our Free Unlimited Stable Diffusion Generator.
Platform for creating artwork from descriptions.
Unleash Your Creativity with Ultra Realistic AI Art
Image generator based on input text.
Generating images for websites and products.
Advanced art platform with rendering and collaboration.
Collaborative art and image editing platform.
Generated images for creative projects.
Create and share art using a collaborative platform.
Generates unique art via web app.
Wall art generated for home decor.
Generated unique images and art platform.
Generated images.
Cloud platform generating free graphics/images.
Effortless copyright-free image creation.
Creating and manipulating digital content.
Online image generation from written ideas.
Streamlined image generation for creatives.
Generated art without coding or installation.
A mobile app that generates images from text.
App to generate realistic and dynamic art.
Generated images from text for design and illustration.
Art and music creation using artificial intelligence.
Creative image generation for artistic inspiration.
Create stunning visuals with hidden texts or images.
Create personalized art without coding.
Collaborative platform for software development.
Create styled illustrations with upscale option.
Generated custom images.
Generated images and text for design ease.
Art creation app using text prompts on mobile.
Image and video manipulation and generation.
Generated images and text for design ease.
Variety creation of images for all designs.
Generated high-res images through a platform.
Automatically create unique art and animation.
Unique, inspiring art generation.
Image Generation with user control.
Generated NFT art platform for creative exploration.
Platform for creating anime-style art.
Customized image generation with a variety of options.
Easily create images with generative artificial intelligence.
Fast image creation based on text input.
Create pro artwork w/ advanced image processing.
Web-based content creation with GPU-powered models.
Generates images for websites.
Web images generated with Stable Diffusion
Imagen2 on Vertex AI: Enhanced Text-to-Image Technology
Simple interface generates images from text.
Image customization using natural language descriptions.
Innovative creation of neural networks.
Image creation from descriptive input.
Creating diagrams through node and edge manipulation.
Generates unique art from text prompts.
Image generator for personalized and unique visuals.
Digital art creation and NFT marketplace.
An app for generating unique artwork and editing photos.
Portrait creation through advanced algorithms.
Generating high-quality images based on prompts.
Generate and sell images for Discord artists.
Software for digital drawing and painting.
Generated online images for social media.
Generated artistic images with prompts.
Sketchpad for creating digital art.
Image generation with unique styles and fast results.
A platform for hosting and monetizing diffusion models.
Image editing solution
Create stunning photos with AI-Picmojo.
Art generation from text inputs.
Creation of diverse visual and auditory content.
Customized framed artwork generated by algorithms.
Generates images from text prompts.
Create varied styles of personal project images.
Create stunning images from text with our powerful AI tool.
Generated captions for mobile images and texts.
Image generation
Generated artistic creations.
Printed creative artwork on various products.
Enhanced eCommerce catalog for superior experience.
Art image generation
Generated image and art prompts.
Customizing generative image models.
Image generation for creative inspiration.
A user-friendly photo editor with written instructions.
Customizable clothing purchase and design.
Image creation from text with customized style.
High-quality image generation for different purposes.
Creates custom digital art from text inputs.
Text-to-image generation for creative visuals.
Quality images from text.
Unleashed artistic creativity.
High-quality image generation for marketing campaigns.
Exploring emotions through interactive art images.
Avatar and mockup generation for professionals.
Create amazing art, get inspired, make your masterpiece.
Explore your artistry with fast and free AI art generator online.
Generate professional images
Creative platform for content and idea generation.
Custom concept-themed images created.
App for generating and customizing stunning images.
Generation of prompts for text, images, and art.
Image generation for writers and creatives.
Generated art from text descriptions.
Creating the perfect AI image within reach.
Photorealistic image generation with custom settings.
Artistic image generation/editing.
Unlimited images for exploration and creation.
Artwork generation for artists and designers
A design generator using a vast image library.
Creation of artistic visuals without human intervention.
Customizable image generation with guided manipulation.
On-device image generation without cloud support.
Creation of personalized avatar images.
Generate digital artwork on mobile devices.
Creation of digital art in various styles.
Generated personalized portraits and landscapes.
A program to generate unlimited images from text.
Custom avatars and headshots, generated automatically.
Run Stable Diffusion models for AI image generation.
Real-time AI guided by your hand for enhanced drawing.
Image art generator based on text input.
Human portrait generator for visual content creation.
Image generator for creative image manipulation
High-quality image generation and enhancement platform.
Image generation
Generated images and art made easy.
Visually captivating images effortlessly generated.
Online image generation for quick visual content.
Image generation GUI for Windows users.
Creating high-quality AI-generated images.
Generated visuals for designers and content creators.
Image manipulation using stable diffusion models.
Explore creatively through generated images.
Rapidly generate diverse images
Instantly generates artwork in various styles.
Paint, but with AI!
Generated visually striking images.
Art sharing platform for generative enthusiasts.
Create custom images for various purposes easily.
Created visual content for business and product.
Creating high-quality images using prompts.
Building with ready-to-use model APIs made easy.
Generated design images in user's style.
Portrait idea search engine for photographers.
Image generation
Artistic logos and graphics generated.
An image generator that produces various styles.
Automated messaging on WhatsApp with impressive images.
Community platform for creating stunning art pieces.
Content monetization platform.
Personalized avatars and generated art.
Creative asset management with generated prompts.
Image customization & generation for diverse needs.
Image sharing platform with rankings and genres.
Revolutionizing visual content creation with AI.
Image and art prompt generation.
Created graphic design images.
Image generator for design & advertising pros.
Generate customized and unique images.
Create custom characters via prompts and poses.
Text-to-image creation and editing software.
Describe an image for Meta AI to generate.
Platform that creates art from text.
Creativity in every photo.
Image generation from text descriptions.
Produce top-quality visuals faster with DomoAI.
Secure login and authentication for user accounts.
Creates unique artwork with user specifications.
A complete Image Generation Studio empowering creators.
Automated artwork creation.
Produce stunning, ad-free images using AI.
Media manipulation for creative artwork.
Content creation and enhancement services.
Personalized high-quality artistic outputs from photos.
Versatile image generation with user-defined styles.
Visual ideas generated by user input.
Generated images made easy for all users.
Personalized photo generation for styles and objects.
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please register to access.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields
![]()
Please complete the form to download the whitepaper.
"*" indicates required fields